もう1つの、DBのかたち、分散Key-Valueストアとは
有限会社スティルハウス
吉川和巳
2009/7/2
RDBとは別の、クラウド時代のデータベースとして注目を浴びている「分散Key-Valueストア」。その本命ともいえる、Googleの数々のサービスの基盤技術「Bigtable」について徹底解説
 クラウド時代のデータベース「分散Key-Valueストア」
クラウド時代のデータベース「分散Key-Valueストア」
| 今回の主な内容 ・クラウド時代のデータベース 「分散Key-Valueストア」 ・分散KVSとRDBは何が違うのか? ・RDBが超えられない「CAP定理」のカベ ・分散KVSの「使いにくさ」に対応する、 2つの利点 ・クラウドによる「IT補完計画」が始まった |
グーグルがインターネットの世界をここまで席けんできた最大の理由は何でしょうか。実は、それは同社の優れた検索技術ではありません。グーグルが成し遂げた最も大きなブレークスルーの1つは、同社が生み出した巨大な分散データストア、「Bigtable」にあります。
Bigtableは、Google検索をはじめ、YouTubeやGoogle Map、Google Earth、Google Analytics、Google App Engineなど、グーグルの70以上のプロジェクトの基盤として利用されています。合計で数PB(ペタバイト)に達する天文学的規模のデータを、全世界36カ所以上のデータセンターに配置された数万~数十万台のサーバに分散して格納し、これらグーグルの各種サービスの圧倒的なスケーラビリティと高可用性を低コストで実現しています。

■ 分散KVSは、「クラウド」という地殻変動の原因の1つ
Bigtableは、リレーショナルデータベース(以下、RDB)ではなく、いわゆる「分散Key-Value Store(以下、KVS)」の1つです。KVSは、プログラミング言語の連想配列やMapと同様に「Key(キー)」と「Value(値)」のペアからなる、ごくシンプルなデータモデルに基づくデータストアです。KVSは「キー・バリュー型データストア」「Key/Valueストア」などと呼ばれることもあります。
いま、このBigtableを代表とする分散KVSが、あたかも「ロード・オブ・ザ・リング」の"指輪"のような破壊的なパワーを発揮しつつあります。分散KVSは、グーグルの圧倒的な強さの源泉であり、インターネットの世界で起こりつつある「クラウドコンピューティング」という地殻変動の原因の1つでもあります。
■ 知ってますか? いろいろな分散KVS
例えばAmazonでは、大規模データ管理用の分散KVSとして「Amazon Dynamo」を開発して同社のサービス実装に用いているほか、その機能を外部向けサービス「Amazon SimpleDB」として一般公開しています(参考:米アマゾン、Webデータベース「SimpleDB」を開発)。

またマイクロソフトは、同社のクラウドサービス「Windows Azure」にて、分散KVS「Azure Storage Services」を提供予定です。
一方、国内でも、楽天では大規模分散データストア「ROMA」を開発し、サービスへの導入を検討している段階です(参考:大規模分散処理向けの国産"ウェブOS"をRubyで開発中)。
■ ほかにもKVS型データ管理システムが流行中
さらに、Apache Software Foundationの「Apache CouchDB」は、並列プログラミング言語「Erlang」で実装されたスケーラビリティの高いドキュメント指向データベースとして、高い注目を集めています。

CouchDBについては、下記をご参照ください。
| ゆったリラックス! CouchDBがあるところ ドキュメントを手軽にWebで公開したいとき、リレーショナルデータベースで実装することに違和感を覚えることはありませんか? CouchDBはそのようなニーズに合った、新しいデータベース管理システムです。CouchDBを知り、リラックスしながら実装をしていきましょう 「Database Expert」フォーラム | ||
mixiでは、自社開発のKVS「Tokyo Tyrant」を用いて高負荷なログイン処理の実装に使用しています。

分散KVSとRDBは何が違うのか?
ではなぜ、クラウドコンピューティングの基盤としてRDB(Relational DataBase)ではなく分散KVSへの移行がいま進みつつあるのでしょうか。この両者のデータモデルやアーキテクチャの違いを比較してみます。
 |
| 図1 RDBと分散KVS |
繰り返しますが、分散KVSは、「キー」と「値」のペアからなる、シンプルなデータモデルに基づくデータストアです。原則、分散KVSは「キーを指定して値を読み書きする」という単純な操作にのみ対応します。
| 表 分散KVSとRDBの比較 | ||||||||||||||||||
|
次ページからは、分散KVSとRDBの違いを具体的に見ていきます。
分散Key-Valueストアの本命「Bigtable」(1)
もう1つの、DBのかたち、分散Key-Valueストアとは
有限会社スティルハウス
吉川和巳
2009/7/2
■ 分散KVSが苦手なトランザクションの「ACID特性」
RDBのように、テーブルとテーブルを結合(SQLでいうJOIN文)して複雑な条件検索や集計処理を一発でこなすような芸当はできません。また、トランザクションによる「ACID特性」の確保も分散KVSが苦手な分野です。
 - @IT")
■ RDBが不得意な分散/拡張
そのため、これらの不足をアプリケーション側で補うためのさまざまな工夫やフォローが必要となります。その一方で、分散KVSはデータストア全体をいくらでも多くのサーバに分散(スケールアウト)できるのが最大の特徴です。
一方でこれは、RDBが最も不得意とするところです。RDBでは、その長所であるテーブル結合やACIDの確保がボトルネックとなり、複数のサーバにスケールアウトさせることが「原理的」に容易ではありません。そのため、負荷分散や高可用性を低コストで実現することが困難です。
■ RDBで負荷分散させようとすると……
例えばMySQLを使う場合、1テーブルのレコード件数が数百万~数千万件を超えるような規模になると、1台のDBサーバだけでは実用的なパフォーマンスが達成しにくくなります。そこで一般には、以下のような対策によってRDBのスケーラビリティを引き上げる努力が必要となります。
- RDBサーバのスケールアップ(大型サーバへの載せ替え)
- DBのレプリケーションやシャード(パーティション)分割によるクラスタ構築
- 分散キャッシュ(Oracle RACやmemcachedなど)によるクラスタ構築
経験者ならばお分かりいただけるとおり、このどれもが結果的に「高コスト」となるソリューションです。
大型サーバやOracle RACが高価なのは当然ですが、オープンソース実装を駆使してシャード分割を実装する場合も高い技術スキルを持つ人材が要求され、システム障害のリスクを抑えるためには周到な設計やテストが必要です。Oracle RACの詳細は、下記記事を参照してください。

レプリケーションやmemcachedも、検索処理のスケールアウトには効果がありますが、更新処理やテーブル結合のスケールアウトにはあまり効果がありません。memcachedの詳細は、下記記事を参照してください。
 - @IT")
これらの理由により、RDBがある一定の規模に成長してクラスタ構築が必要になると、システム開発コストはけた違いに上昇していきます。
■ 分散KVSは「グーグルのビジネスモデルそのもの」
そもそも、RDBのデータモデルは原理的にスケールしにくく、これらの対策は対症療法的な側面があります。一方で、分散KVSのデータモデルは原理的にスケールしやすく、実用上は無制限に近いスケーラビリティ(負荷分散と高可用性)を低コストで達成できます。
グーグルが検索サービスのデータストアとしてRDBを選ばなかった理由は、ここにあります。むしろ、機能豊富なRDBをあえて使わず、シンプルな分散KVSによって無制限なスケーラビリティを低コストで実現することこそが、「グーグルのビジネスモデルそのもの」といっても過言ではありません。
RDBが超えられない「CAP定理」のカベ
2000年にUC Berkley大学のEric Brewer教授が発表した「CAP定理」では、分散システムで以下の3つを同時に保証することは不可能であることが示されています。
- データの整合性(Consistency)
- データの可用性(Availability)
- データの分散化(Partition-tolerance)
■ RDBとは、そもそもスケールしにくいものだ
一般的なRDBでは、トランザクションに含まれるすべてのデータについて、ACID特性(CAPのC)を保証します。これはつまり、可用性(同じくA)と分散化(同じくP)の間にトレードオフが発生することを意味します。負荷分散と冗長化のためにRDBをクラスタリングすると、整合性確保のためにそれぞれのデータが高頻度でロックされ、スケーラビリティは頭打ちになってしまいます。これが、「RDBは原理的にスケールしにくい」理由の1つです。
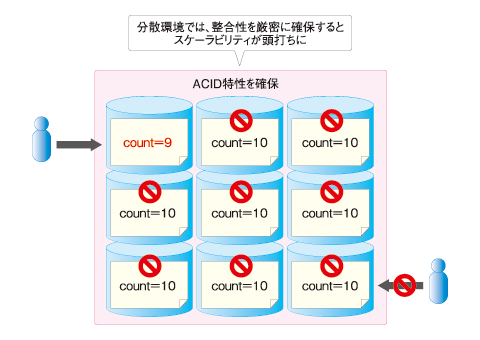 |
| 図2 CAP定理が示すRDBの限界 |
■ アプリケーションが分散化対応するための必須条件
一方、例えばBigtableでは、可用性と分散化を損なわないために、ACID特性の保証が一定範囲に限定されています。よってプログラマは、個々のアプリケーションについてACID特性の要件を見定め、Bigtableの能力でそれに対応できるか判断したり、アプリケーションの設計を工夫したりする必要が生じます。また、決済業務など厳格なACID特性が要求される用途では、Bigtableを適用しにくいケースも少なくないはずです。
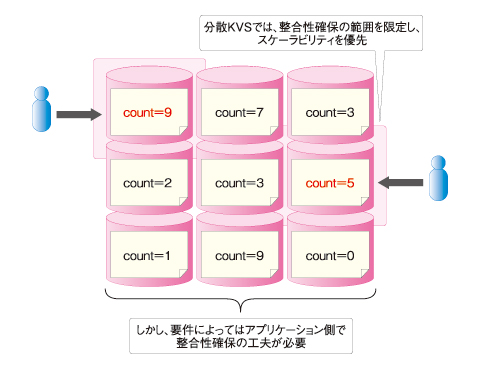 |
| 図3 分散KVSのスケーラビリティと「使いにくさ」 |
こうしたさまざまな制約や実装の面倒さはRDBにはなかったものですが、それがアプリケーションの分散化に際して避けて通れないものであることは、CAP定理が証明するところです。
つまり、分散KVSのさまざまな「使いにくさ」(「ACID特性が限定される」「テーブル結合ができない」「検索・集計機能が貧弱である」など)をアプリケーション側でフォローすることは、裏を返せば「アプリケーションが分散化対応するための必須条件」なのです。
次ページで、その「使いにくさ」に対応することによって得られる2つの利点を解説し、最後に分散KVSとクラウドについてまとめます。
もう1つの、DBのかたち、分散Key-Valueストアとは
有限会社スティルハウス
吉川和巳
2009/7/2
分散KVSの「使いにくさ」に対応する、2つの利点
分散KVSの「使いにくさ」にわれわれがいったん順応してしまうと何が起きるかは、グーグルの各種サービスの成功例や、同社が提供するクラウドサービス「Google App Engine(以下、App Engine)」の圧倒的なコストの低さ(無償)を見れば明らかです。App Engineで実際にアプリケーションを作ってみたい読者は下記連載を参考にしてください。App EngineからのBigtableの操作の仕方なども分かります。

■ 利点その【1】負荷分散や可用性に悩まないでいい!
まず、実用上は制限のないスケーラビリティのおかげで、「負荷分散や可用性のことで悩んだりコストを掛けたりする必要があまりなくなる」ということです。
■ 利点その【2】データを効率よく集約できる!
そしてもう1つの、かつ最も重要な利点は、「アプリケーションの分散化対応によって、クラウドによる全体最適のメリットを享受できる」ことです。
分散KVSの「使いにくさ」を受け入れると、クラウド側ではアプリケーションのデータをクラウドのどこにでも自由に配置・移動・分割でき、多数のアプリケーションのデータを極めて効率よく集約(コンソリデーション)できるようになります。
App Engineのように1台のサーバで多数のアプリケーションを収容するクラウドサービスでは、個々のアプリが1つの仮想マシンやOS、DBインスタンスを占有して多大なサーバリソースを消費することがありません。このようなアプリケーションの分散化対応によってクラウドの全体最適が達成され、個々のアプリケーションの運用コストが飛躍的に下がります。
■ 例えるなら、「一戸建て」と「タコ部屋」である
これは例えるなら、独立した仮想マシンやOS、DBインスタンスを占有していた「一戸建て」の環境を捨て、100人くらいで1つの部屋を共有する「タコ部屋」に入居するようなものです。このタコ部屋では、分散KVSという使いにくい収納しかありません。
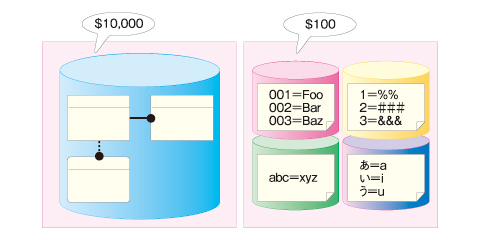 |
| 図4 「一戸建て」と「タコ部屋」 |
その代わり、賃料が2けたくらい安いうえに、この収納には荷物をいくらでも詰め込めます。また部屋が満杯になったり火事で焼失しても、すぐ別の部屋に移動できます。
クラウドによる「IT補完計画」が始まった
このように考えると、分散KVSとは実は「クラウドによる全体最適のメリットを享受するための分散化のプラクティス」であることが分かります。分散KVSを使用するには、RDBのACID特性やテーブル結合、洗練された検索・集計機能の利用をあきらめ、アプリケーション側でそれらの不足を補うさまざまな工夫や追加のコーディングが必要になります。
しかし、そうした「分散化に避けて通れないプラクティス」を受け入れることで、個々のアプリケーションが単体のサーバや仮想マシン、OS、DBインスタンスを占有する無駄がなくなり、クラウドという一体化した巨大インフラへの究極のコンソリデーションが実現します。
これにより、スケーラビリティや負荷分散、高可用性に関する課題がほぼ解消され、同時にかつてないほどの低コストでアプリケーションの運用が可能になります。グーグルの成功やCAP定理は、クラウドコンピューティングの本質がそうしたパラダイムシフトであることを示しています。
最後に、このパラダイムシフトにぴったり当てはまる"セリフ"を、アニメ「エヴァンゲリオン」から引用したいと思います。
「出来損ないの群体として行き詰まった人類を、完全な単体生物へ人工進化させる」(エヴァンゲリオンの人類補完計画)
これを、次のようにいい換えると、いま「クラウドコンピューティング」によって起きていることをいい表せます。
「出来損ないの群体として行き詰まったITシステムを、完全な単体インフラへ人工進化させる」(クラウドによるIT補完計画)
群体だったITシステムが単体であるクラウドへと融合し、究極の全体最適を実現するうえで、分散化に対応できないRDBは足かせとなります。分散KVSというグーグルが見つけた"指輪"の正体は、この「クラウドへの進化」そのものといえるでしょう。
以上、今回は分散KVSとは何かを紹介し、それが意味するところを考えてみました。次回は、いよいよ分散KVSの本命であるグーグルのBigtableの内部構造に切り込んでいきたいと思います。
分散Key-Valueストアの本命「Bigtable」(2)
素朴なBigtable、できること できないこと
有限会社スティルハウス
吉川和巳
2009/9/7
RDBとは別の、クラウド時代のデータベースとして注目を浴びている「分散Key-Valueストア」。その本命ともいえる、Googleの数々のサービスの基盤技術「Bigtable」について徹底解説
あまりにもRDBとは異質な「Bigtable」
| 今回の主な内容 ・あまりにもRDBとは異質な「Bigtable」 ・Bigtable、3つの特長 ・Bigtableは「検索」ができない!? ・どう動いてる? Bigtableの「中の人」 ・Bigtableは"素朴"。だから、使い方が重要 |
前回の「もう1つの、DBのかたち、分散Key-Valueストアとは」では、連載第1回目として、クラウドコンピューティングにおける新しい潮流である「リレーショナルデータベース(RDB)から分散Key-Valueストア(分散KVS)への移行」が、どのようなパラダイムシフトをもたらすのかを解説しました。今回からは、グーグルが運用する代表的な分散KVS「Bigtable」の内部構造を紹介し、クラウドの本質をより深く掘り下げます。
前回も説明したとおり、Bigtableは、Google検索をはじめ、YouTubeやGoogleマップ、Google Earth、Google Analytics、Google App Engineなど、グーグルの70以上のプロジェクトの基盤として利用されています。合計で数Pbytes(ペタバイト)規模のデータを全世界に散らばる数十万台のサーバに格納した、「超」巨大な分散データストアです。

Google サービス一覧 via kwout
Bigtableは、行と列からなる「テーブル」と呼ばれる構造を備えます。このテーブルは、簡単にいえば「Excelの表」のようなものです。個々の行は「キー」を用いて読み書きが可能です。さらに、テーブルのセルに当たる個々のデータは、履歴を残すことが可能です。
例えば以下では、「com.cnn.www」というキーに基づいて、それに対応するコンテンツやリンク情報、さらにはそれらの履歴を保存しています。
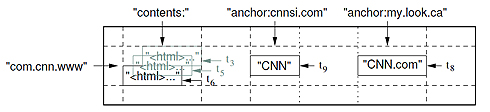 |
| 図1 Bigtableのデータモデルの概念図(引用元:グーグル「Bigtable: A Distributed Storage System for Structured Data」) |
Bigtable、3つの特長
Bigtableは、以下の3つの特長を備えます。
■ 【1】実用上、無制限のスケーラビリティ
まずBigtableのテーブルには、実用上はスケーラビリティに上限がありません。テーブルの規模が100件でも、数千万件でも、個々の行の読み書きは数10ms(ミリ秒)程度で完了します。また、膨大な数のユーザーがBigtableに同時にアクセスしても、レスポンスの低下は発生しません。
実際、グーグルの各種サービスを使う人なら「世界中のものすごい数のユーザーが同時にアクセスしているはずなのに、サーバが重くならないな」という疑問を持ったことがあるはずです。一般的なWebアプリケーションの大半では、RDBサーバがボトルネックとなってデータ量やアクセス件数の増加にともない、レスポンス時間が遅くなりますが、Bigtableを使ったWebアプリケーションでは、それが皆無です。
この「まったく異なる次元のスケーラビリティ」こそ、「"Big"table」という名の由来となっています。
■ 【2】サーバ冗長化による高可用性
もう1つの特長は、可用性の高さです。Bigtableにデータを1件書き込むと、グーグル独自の分散ファイルシステム「Google File System(GFS)」を通じて、異なるラックに設置された3台以上のサーバにコピーされます。そのため、サーバ障害によってデータが失われる可能性は極めて低いうえに、いずれか1台のサーバが停止してもほかの2台のいずれかから同じデータを瞬時に取得できます。

加えて、Bigtableのサービスを構成するサーバ群はすべてが冗長化されており、SPoF(Single Point of Failure)は排除されています。こうした冗長構成によって、Oracle RAC(Real Application Clusters)などのハイエンドのRDBクラスタに匹敵する高可用性を備えています。

多様化するクラスタ方式 via kwout
■ 【3】圧倒的なコストの低さ
Bigtableの3つめの特長は、圧倒的なコストの低さです。例えば、グーグルが提供するクラウド・サービスである「Google App Engine(以下、App Engine)」では、初期費用をまったく支払わずにBigtableを含むすべての機能を利用できます。これに対し、上述したようなハイエンドのRDBクラスタの構築には一般に数千万円規模のコストが掛かります。
また利用開始後は、Bigtable上に保存したデータ量や消費したCPU時間に応じて従量課金となりますが、これは事実上「ほとんどタダ」で済みます。
例えば、筆者が実際に担当した既存WebアプリケーションからApp Engineへの移行案件において、合計400万件程度(総容量11Gbytes)のデータをBigtable上に保存したところ、グーグルから請求された月額費用は4ドル程度でした(にわかには信じがたいと思いますので、以下のダッシュボード画面に表示されたコストをご確認ください)。
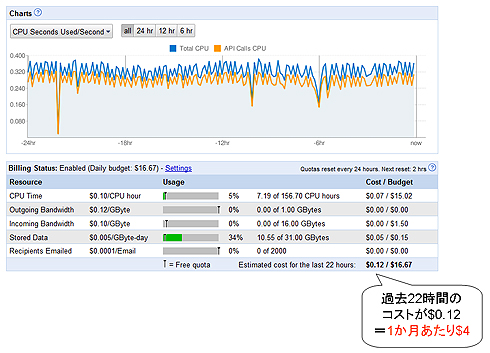 |
| 図2 Google App Engineの運用コストの例(ダッシュボード画面) |
つまり、よほど大量のデータやトラフィックを扱わない限り、大半のWebアプリケーションはほとんど無料で運用できます。
次ページでは、Bigtableがケタ違いのスケーラビリティやコストパフォーマンスを実現できる理由や、Bigtableがどのようなシステム構成によって実装されているのかを見ていきます。
素朴なBigtable、できること できないこと
有限会社スティルハウス
吉川和巳
2009/9/7
Bigtableは「検索」ができない!?
ではなぜ、Bigtableはこのようなケタ違いのスケーラビリティやコストパフォーマンスを実現できるのでしょうか。
その理由の1つは、前回も説明したとおり、それがRDBではなく「キーを指定して値を読み書きする」という、ごく単純な機能しかサポートしていないことにあります。よって、Bigtableの「テーブル」とRDBの「テーブル」は、名前こそ似ていますが、それらの機能や性質は大きく異なります。
Bigtableにできることは、以下の2種類の処理だけです。
■ 【1】キーに基づく行のCRUD
「キーに基づく行のCRUD」とは、個々の行に割り当てられた「キー」を指定して、行のCRUD(追加、取得、更新、削除)を行うことです。このCRUDに際しては、ACID特性が保証されており、例えば2件の更新処理がある1行に集中してそれぞれが書き込んだ値が混在してしまうようなことは起きません。
なお、Bigtableでは複数行に渡るCRUDについてはACID特性が確保されませんが、App Engineでは、これを補う形で特定範囲内の複数行のACIDを保証する機能を提供しています。
■ 【2】キーに基づく「スキャン」
一方、「キーに基づくスキャン」とは、キーの前方一致検索もしくは範囲指定検索により、複数の行を一括取得する機能です。以下の図3をご覧ください。
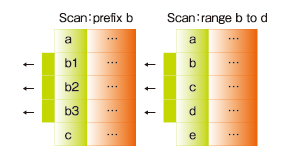 |
| 図3 「キーによるスキャン」の例(出典:グーグル「Under the Covers of the Google App Engine Datastore」Ryan Barrett著) |
このように、例えば「bで始まるキーを持つすべての行を取得」したり、「b~dで始まるキーを持つすべての行を取得」したりできます。
どう動いてる? Bigtableの「中の人」
最後に、グーグルのクラウドの内部では、このBigtableがどのようなシステム構成によって実装されているのかを説明します(なお、以後紹介する内容は2006年時点で公開された情報に基づいているため、2009年9月現在は変更されている可能性もあります)。
■ Bigtableのデータは「タブレット」単位で分かれる
ご存じのとおり、グーグルのクラウドの特徴は、「高価な高性能サーバは使用せず、安価なPCサーバを大量に並べて負荷分散と高可用性を実現している」という点です。Bigtableはその典型例で、以下のようなグーグルの典型的なPCサーバ上で稼働しています。
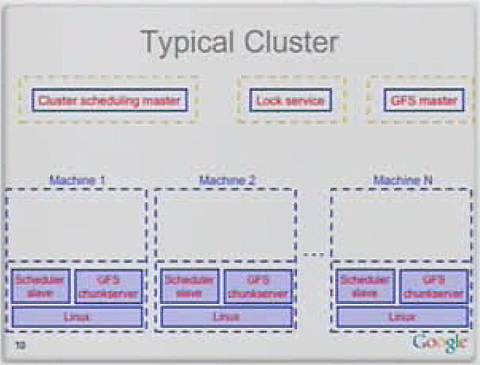 |
| 図4 グーグルのデータセンターにおける典型的なクラスタノード構成(引用元:グーグル「Big Table: A Distributed Structured Storage System」Jeff Dean著) |
グーグルのデータセンターには、こうしたPCサーバが数万台規模で並んでいます。これらのうち、Bigtableが稼働する個々のPCサーバは、以下のような構成になっています。
- Linux OS
- Bigtableタブレットサーバ
- GFSチャンクサーバ
「Bigtableタブレットサーバ」とは、Bigtableのテーブルのデータを100~200Mbytes程度の大きさに分割した「タブレット」を管理するサーバです。1台のタブレットサーバは100個以下のタブレットを保存しますので、PCサーバ1台当たり約10~20Gbytes程度を管理する計算になります。
タブレットサーバが管理するタブレットのデータは、先に述べたとおり分散ファイルシステムGFSの「チャンク」と呼ばれる形式で保存されます。このとき、タブレットサーバと同じPCサーバ上の(=ローカルの)「GFSチャンクサーバ」を優先して保存先に選びます。また、同じデータのコピーをほかの2つのGFSチャンクサーバにも保存します。
よって、例えば100個のタブレットを持つあるPCサーバがダウンしたり過負荷状態に陥っても、同じタブレットを持つほかの100台のPCサーバが処理を引き継ぐため、利用者がPCサーバの障害や過負荷に気付くことなくサービスを継続運用できる仕組みです。
■ Bigtableのキャッシュメカニズムはオーソドックス
またBigtableは、データモデルこそRDBとはまったく異なるものの、キャッシュメカニズムなどの内部構造は、意外にオーソドックスな設計となっています。
例えば、Bigtableのテーブルに対して読み書きされた内容は、まず「memtable」と呼ばれるメモリ上のキャッシュに保存し、一定間隔でディスクに保存する仕組みです(「minor compaction」)。もちろん、キャッシュ内容が失われる場合もあるので、読み書き履歴は「コミットログ(ジャーナルログ)」としてディスクにも保存されます。この辺りの仕組みは、例えばOracleデータベースのREDOログやDBWRプロセスなどのメカニズムとよく似ています。
また、GFS上へのデータを書き込む際には、PostgreSQLと同様に「既存のデータは一切変更せずに、変更内容を追記していく」という方式を採用しています。これによりロックの不要な読み込みアクセスや負荷分散を実現していますが、同時に定期的に削除済みデータをGC(ガベージコレクション)する仕組みも用意されています(「major compaction」)。これはPostgreSQLの「vacuum」と同様のメカニズムです。
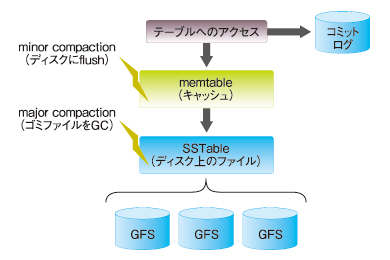 |
| 図5 Bigtableのキャッシュメカニズム |
Bigtableは"素朴"。だから、使い方が重要
Bigtableにできることは、これだけです。ちょっとびっくりするかもしれませんが、Bigtableでは「値を条件に行を検索する」という、RDBではごく当たり前の検索処理(クエリ)をまったくサポートしていません。「それでどうやってアプリケーションを実装するのだろう?」と疑問を持つ方も多いはずです。筆者もBigtableを学び始めたときは、そう思いました。
しかし、いくつかの手法を組み合わせることで、こんな"素朴"な仕様のデータストアであっても数多くのWebアプリケーションを実装可能です。実際、先に示したYouTubeやGoogleマップ、Google Earthといったメジャーなサービスは、いずれもこうした制約の範囲内でBigtableを駆使しながら豊富なサービス機能を実装しています。
またApp Engineでは、Bigtable上で簡単なクエリやCRUDを実装した「Datastore API」を提供しています。そこで次回は、このDatastore APIについて詳しく紹介し、現実的なWebアプリケーション開発ではBigtableをどのように使いこなせるのかを紹介する予定です。
分散Key-Valueストアの本命「Bigtable」(3)
ここが大変だよBigtableとGoogle App Engine
有限会社スティルハウス
吉川和巳
2009/11/11
RDBとは別の、クラウド時代のデータベースとして注目を浴びている「分散Key-Valueストア」。その本命ともいえる、Googleの数々のサービスの基盤技術「Bigtable」について徹底解説
月間3000万PVの大規模サイトの運用費が月額4万円!?
| 今回の主な内容 ・月間3000万PVの大規模サイトの運用費が月額4万円!? ・繰り返すが、Bigtableの検索機能は「スキャン」だけ ・Datastoreサービスと3つのAPI ・2つのインデックス「シングルプロパティ」「コンポジット」 ・そのほかのDatastoreクエリの"大変"なトコロ ・逆に「複雑なクエリやジョインなんていらないさ」 ・結局、DatastoreのAPIはどれがいいの? |
月間3000万PV相当の膨大なトラフィックを楽々とさばく大規模サイトが、月額4万円弱で運用されている。
Google App Engine(以下、App Engine)が普及するにつれて、そんな驚愕の国内事例も登場しつつあります。GClueがApp Engine上で実装したmixiアプリモバイルには、1日100万PV以上のアクセスが集中している状態でもサービスのレスポンス低下やダウンは皆無だそうです。1日の運用コスト(グーグルへの支払い料金)は$12程度で、プログラマ以外に専任のサーバ管理者などはまったく不要とのことです。
こうしたApp Engineのけた違いのスケーラビリティやコストパフォーマンスといった大きな「価値」を得るには、われわれエンジニアがそれ相応の「発想の転換」を受け入れる必要があります。
前回の「素朴なBigtable、できること できないこと」でも説明したとおり、App Engineの中核をなすデータストア「Bigtable」は、「キーを指定して値を読み書きする」という単純な機能しかサポートしていない分散Key-Valueストア(分散KVS)です。この素朴なデータストアの大きな制約を受け入れ、そのうえで複雑なWebアプリケーションのロジックをいかにして実装できるか工夫していくことが、この発想の転換へのはじめの一歩となります。
繰り返すが、Bigtableの検索機能は「スキャン」だけ
前回も説明したとおり、Bigtableは、リレーショナルデータベース(RDB)におけるクエリやジョインを一切サポートしておらず、以下の2種類の機能だけを提供しています。
- キーに基づく行のCRUD
- キーに基づく「スキャン」
「キーに基づく行のCRUD」とは、個々の行に割り当てられた「キー」を指定して、行のCRUD(追加、取得、更新、削除)を行うことです。一方、「キーに基づくスキャン」とは、キーの前方一致検索、もしくは、範囲指定検索により、複数の行を一括取得する機能です。
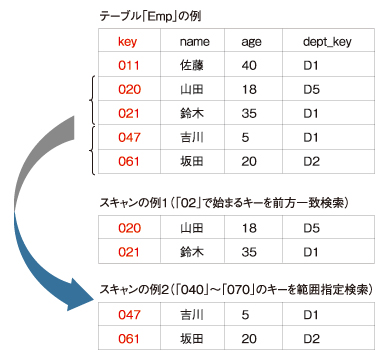 |
| 図1 「キーによるスキャン」の例 |
例えば上記の「スキャンの例1」では、テーブル「Emp」に対して、キーが「02」で始まる行を前方一致検索でスキャンし、「山田」「鈴木」という2行を取得しています。また「スキャンの例2」では、キーが「040」から「070」までの行を範囲指定検索でスキャンし、「吉川」「坂田」の2行を得ています。
Bigtableが備える唯一の検索は、このスキャンだけです。つまり、値を条件とした検索は一切実行できません。Bigtableについて学び始めた当初、筆者は「これでどうやってアプリケーションロジックを書くのだろう」と悩みました。しかし、App Engineでは、この問いに答えるソリューションを提供しています。それは、Bigtable上でRDBライクなクエリ機能を実装する「Datastoreサービス」です。
Datastoreサービスと3つのAPI
Datastoreサービスとは、App Engine上で動作するPythonもしくはJavaアプリケーションがBigtableにアクセスするためのサービスであり、主に以下の3つの機能を提供します。
- キーに基づくエンティティのCRUD
- エンティティに対するクエリ
- 複数エンティティを対象としたトランザクションのACID保証
ここで「エンティティ」とは、PythonやJavaの個々のオブジェクトを保存したBigtableの行を表します。Datastoreサービスでは、このエンティティに対してキーに基づくCRUDが可能です。加えて、RDBライクな「クエリ」によるエンティティの検索を実行できるのが重要なポイントです。App EngineのJava版の場合、これらのDatastoreサービスの機能は、以下の3つのAPIを通じて利用できます。
- JDO(Java Data Objects)
- JPA(Java Persistence API)
- 低レベルAPI(Low-level API)
これらのうち、「JDO」および「JPA」は、JCP(Java Community Process)を通じて策定された標準のデータ永続化APIです。とはいえ、JDOやJPAの機能をフル実装しているわけではなく、あくまで「Bigtableで実装できる機能のみ標準APIに合わせて提供している」といった位置付けです。
一方、低レベルAPI(以下、LL)はApp Engine独自のAPIであり、ほかの2つのAPIに比べてより"生の"Bigtableに近い機能を提供します(なお、以下ではJDOに基づいて説明を続けますが、これら3つのAPIのいずれを選択すべきかについては、本稿最後の章をご覧ください)。
■ キーに基づく行のCRUD
さて、1つめの機能である「キーに基づくエンティティのCRUD」は、先に記したBigtableの「キーによる行のCRUD」と同じ機能です。以下は、JDOによるエンティティ保存の記述例です。
PersistenceManager pm = PMF.get().getPersistenceManager(); Emp e = new Emp("山田", 18, "D5"); try { pm.makePersistent(e); } finally { pm.close(); }この例のように、PersistentManagerクラスのmakePersistent()メソッドに続いてcloseメソッドを呼び出すことで、JavaオブジェクトであるEmpをBigtableの1行として保存できます。ちなみに、こうしたCRUD処理に要する平均時間は数10ms程度で、前回説明したとおり、たとえ数千万件のエンティティが保存されていても処理時間は変化しません。
またBigtableでは、ACID特性の保証の範囲が行単位であったのに対し、Datastoreサービスでは「エンティティ・グループ」と呼ばれる複数のエンティティの集まりを対象としてACID特性の保証が可能です。よって、例えば「Deptエンティティ」と「Empエンティティ」を同じエンティティ・グループに含めておけば、トランザクションの競合時でも不整合の発生を防ぐことができ、一般的なRDBと同等の信頼性を確保できます。
■ Datastoreサービスの「クエリ」
Datastoreサービスのもう1つの機能である「クエリ」とは、エンティティのプロパティ(フィールド)の値を条件とする検索機能です。以下は、JDOを用いてクエリを実行するコードの例です。
uery query = pm.newQuery("select from Emp " +
"where age >= _startAge & age <= _endAge " +
"order by age asc " +
"parameters int _startAge, int _endAge")
List<Emp> results = (List<Emp>) query.execute(20, 40);この例では、JDOが定めるSQLライクなクエリ言語である「JDOQL」でクエリ条件を記述し、Queryオブジェクトのexecute()メソッドを呼び出してクエリを実行しています。上記のクエリは「ageプロパティが20~40のEmpエンティティ一覧を取得し、ageプロパティの昇順でソートする」という意味です。こうしたクエリは、通常150~200ms程度の時間で処理されます。
このように、一見するとDatastoreではRDBのような「テーブルのカラム値を条件とした検索」が実行できているように見えます。しかし繰り返し説明したとおり、Bigtableはあくまで「スキャン」しか実行できません。この間を埋めるカギが、「シングルプロパティインデックス」です。次ページで解説します。
2つのインデックス「シングルプロパティ」「コンポジット」
■ 「シングルプロパティインデックス」がカギ
Datastoreサービスでは、あるテーブルに含まれるすべてのエンティティについて、すべてのプロパティ(テーブルのカラムに相当)の値をキーとして並べた「シングルプロパティインデックス」と呼ばれるインデックステーブルが自動的に作成されます。
例えば、テーブルEmpが備える「name」「age」「dept_key」という3つのプロパティについて、「テーブル名+プロパティ名+プロパティ値」をキーとし、「Empテーブルの各行のキー」を値とする以下のようなインデックステーブルが作成されます。
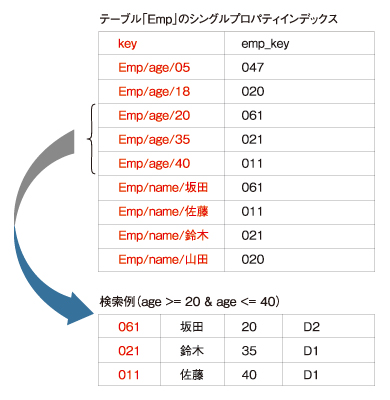 |
| 図2 シングルプロパティインデックスによるクエリの例 |
Datastoreサービスでは、このシングルプロパティインデックスを用いることにより、アプリケーションが実行するクエリを「インデックスとスキャンの組み合わせ」に背後で変換しています。
例えば、上述の「age >= 20 & age <= 40」という範囲検索のクエリは、上記例のシングルプロパティインデックスのキー「Emp/age/20」から「Emp/age/40」までのBigtableスキャンに変換されます。これはいわば、「想定されるすべてのクエリの検索結果をあらかじめインデックステーブルに並べておくようなもの」です。
■ 「コンポジットインデックス」は必要最小限に
しかし、こうしたDatastoreサービスのクエリ機能は、あくまでも「RDB風な条件検索をBigtableでまねたもの」であって、実際のRDBのクエリやジョインが提供する機能に比べて数多くの制約や制限を抱えています。
例えば、シングルプロパティインデックスによるクエリでは、「あるプロパティを対象に不等号(>、>=、<、<=)を使って範囲指定してしまうと、同じクエリ上でほかのプロパティを条件指定に含められない」という制限があります(なお、等号「=」による条件指定のみであれば複数プロパティを同時に使用できます)。
よって、例えばプロパティageの範囲指定だけでは、対象エンティティ数が数千~数万件に膨らんでしまうような状況であると、実用的な時間内(例えば、数秒程度)でクエリを終了できなくなってしまいます。これがRDBであれば、まずプロパティdept_keyで特定部署に絞り込み、加えてプロパティageの範囲指定を行うことで、対象行を数百行以下に抑えるといった対策が可能です。しかし、シングルプロパティインデックスだけでは、そうした複雑な条件指定に対応できません。
そうした場合は、もう1つの種類のインデックスである「コンポジットインデックス」が利用できます。これは、シングルプロパティインデックスと同様のインデックステーブルを、複数のプロパティ値を組み合わせて作成したものです。なお、コンポジットインデックスを作成するには、App Engineの開発者がXML設定ファイルを通じて明示的に作成を指示する必要があります。
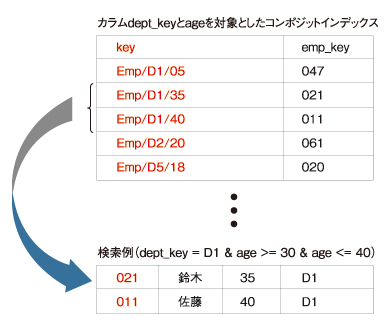 |
| 図3 コンポジットインデックスによるクエリの例 |
このコンポジットインデックスを用いることで、「dept_key = 'D1' & age >= 30 & age <= 40」といった2つのプロパティを条件指定に利用可能になります。
しかし、コンポジットインデックスの問題点は、「あまり安易に多用はできない」という点です。インデックスであるからには、対象のテーブルの行が更新されるたびにインデックスも更新が必要です。よって、コンポジットインデックスを何十個も作成してしまうと、パフォーマンスの低下が懸念されます。
よって、既存のSQL文に含まれる検索条件を次々とコンポジットインデックスに置き換えていくのではなく、「ここぞ」という重要な用途に絞って使う必要があります。
基本的には、シングルプロパティインデックスによるクエリとプログラムコード上でのフィルタリングやソートを組み合わせるのが定石といえるでしょう。
そのほかのDatastoreクエリの"大変"なトコロ
Datastoreによるクエリには、ほかにも以下のようなさまざまな制約があります。
■ テーブルの結合(join)ができない
Datastore APIの最大の制約は、やはりテーブルの結合(join)ができない点です。その対処として、結合対象となる個々のテーブルへのクエリを個別に実行する方法や、テーブル設計を非正規化し結合済みのテーブルとする方法があります。
またDatastore APIでは、エンティティに「List Property」と呼ばれる複数の値を保持するプロパティを持たせることができるので、これを利用して一対多の関連を表現できます。
■ クエリ構文の制約
クエリの構文には多数の制約があり、その代表が「LIKEによる部分一致検索ができない」というものです(前方一致検索はサポートする)。よって全文検索を実施したい場合は、検索対象の文字列からキーワードを切り出した転置インデックスをアプリケーション側で作成して利用する必要があります。
またクエリでは、「OR」「!=」が使えないほか、不等式条件(「<」「<=」「>=」「>」)を同時に複数のプロパティに適用できない、不等式条件に指定したプロパティが最優先でソートされるといった制約があります。
■ HTTPリクエストの処理時間は30秒まで
これはDatastore APIの制約ではなく、App Engine全体の制約です。1つのHTTPリクエストに対しては30秒以内にHTTPレスポンスを返す必要があり、その時間を超えると例外が発生する仕組みです。よって、Datastore APIを介して大量のデータにアクセスしたり、バッチ処理を実行したりする場合には、個々の処理を25秒程度で切り上げて、次のリクエストで処理の続きを再開するようなロジックが必要となります。
■ 集約関数や組み込み関数がない
「min()」「max()」「sum()」といった、SQLの集約関数、およびgroup byの機能がサポートされていません。よって、例えば「あるプロパティの最大値」を得るには、そのプロパティの降順でソートするクエリを実行し、最初の1行を得るといった工夫が必要です。
逆に「複雑なクエリやジョインなんていらないさ」
このように、Datastore APIでは従来のRDBでは「当たり前」にできたことがまったくサポートされていないことも少なくなく、相当なワークアラウンドを強いられることもしばしばです。
実際に筆者の開発案件でも、RDB上に構築された既存のスキーマをそのままDatastore APIに載せただけでは、クエリ構文の制約が障害となって要件を満たせない状況が発生しました。そこで、「テーブル結合の代用としてインデックス的に使用するテーブルを新たに追加する」というワークアラウンドで対処しています。
しかし、これらの制約を前向き受け止め、「逆に考えるんだ、複雑なクエリやジョインなんていらないさ」という発想で、「分散KVS時代の新たなデザインパターン」を構築していけるかが、冒頭で紹介した事例のような2けたレベルの劇的なコストダウンを可能にする発想の転換への近道ではないかと筆者は考えます。
結局、DatastoreのAPIはどれがいいの?
App Engineをこれから使おうと考えるJava開発者は、Datastoreサービスが提供するJDO、JPA、そしてLLという3種類のAPIのうちどれを選択すべきかが、悩ましいポイントです。これら3つのAPIのうち、グーグルが最も豊富なドキュメントやサンプルを提供しているのはJDOベースの実装です。
一方、JPAやLLについては、APIドキュメント以外にあまり豊富なドキュメントは用意されていません。そのため、筆者を含め、Datastoreサービスを使い始める方の多くは、まずJDO実装から学んでいます。しかし実はここ数カ月の間に、App Engine Java版の利用者の間からは、JDO実装について、以下のように指摘されるようになりました。
- パフォーマンスが低い(LLのおよそ1/3)
- Bigtable本来の機能から離れ過ぎていて理解しにくい
- バグがある
そのため、App Engineを使いこなす中級者は試行錯誤しながらLLを使い始める方もいます。また、ひがやすを氏が提供するApp Engine対応のMVCフレームワーク「Slim3」に備わる、「Slim3 Datastore」は、LLと同等のパフォーマンスを維持しながら、簡潔で使いやすく理解しやすいAPIを提供しており、急速に導入事例が増えつつある状況です。
| 表 Datastoreサービスの4つのAPIの比較 | |||||||||||||||||||||||||
|
また、Slim3のサイトで公開されているパフォーマンステストツールを使うと、JDOに比べてLLおよびSlim3が3~4倍ほど高速なことを実際に確認できるので、参考にしてみてはいかがでしょうか。
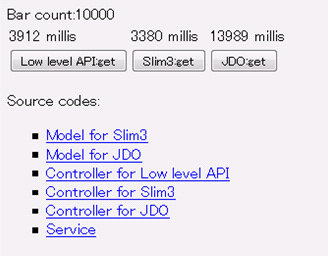 |
| 図4 LL、Slim3、JDOのパフォーマンス比較結果 |
0 件のコメント:
コメントを投稿